はじめに
今回はllama-cpp-pythonとChatbot-uiを用いて、複数のローカルモデルをWebUIベースで扱う方法を紹介いたします。 また、本記事ではDockerを使用して環境を構築いたします。
前提知識
llama-cpp-python
「llama-cpp-python」は、ggerganov氏による「llama.cpp」ライブラリのためのPythonバインディングです。このパッケージは、C APIへの低レベルアクセスと、テキスト完成のための高レベルPython APIを提供します。また、OpenAI互換のウェブサーバーも提供し、ローカルでのCopilot代替や、関数呼び出し、ビジョンAPIサポート、複数モデルのサポートが可能です。 詳細なドキュメントはllama-cpp-pythonのReadTheDocsページにあります。
Chatbot UI
「Chatbot UI」は、OpenAIのチャットモデル用に設計された高度なチャットボットインターフェイスです。Next.js、TypeScript、Tailwind CSSを使用し、プロンプトテンプレート、レスポンス編集、GPT-4統合などの機能をサポートします。カスタマイズと柔軟性を重視しており、開発者はチャットとシステムインターフェイスを簡単に変更できます。
llama-cpp-pythonで複数モデルを扱う方法
まず、軽くllama-cpp-pythonで複数モデルを扱う方法を紹介します。 実際に作業する内容は次項目になります。本項目は飛ばしていただいて構いません。
llama-cpp-pythonではllama-cpp-python[server](以下、lcp[server])というOpenAI互換のAPIサーバが提供されています。こちらの機能を使用することで、OpenAIの公式APIを扱うのと同様の方法でローカルLLMを扱うことができます。
また、昨年12月に、複数モデルを扱えるようにアップデートが実施されました。([Feat] Multi model support #931)
公式ドキュメントを元に複数モデルを扱う方法を紹介します。
従来、llama-cpp-pythonでモデルを扱う場合は以下のようなコマンドで起動していました。
python3 -m llama_cpp.server --model <モデル名> --chat_format <チャットフォーマット>複数モデルを扱うにはまず、以下のようなJSONファイルを作成します。 models内で扱える変数は公式ドキュメントを参照してください。
{
"host": "0.0.0.0",
"port": 8000,
"models": [
{
"model": "1つ目のモデルのパス",
"model_alias": "1つめのモデル名",
"chat_format": "チャットフォーマット",
"n_gpu_layers": -1,
"offload_kqv": true,
"n_threads": 12,
"n_batch": 512,
"n_ctx": 2048
},
{
"model": "2つ目のモデルのパス",
"model_alias": "2つめのモデル名",
"chat_format": "チャットフォーマット",
"n_gpu_layers": -1,
"offload_kqv": true,
"n_threads": 12,
"n_batch": 512,
"n_ctx": 2048
},
]
}JSONを作成したら、「–model」の代わりに「–config_file」を指定し、lcp[server]を起動することで複数モデルを扱うことができます。
python3 -m llama_cpp.server --config_file <config_file>llama-cpp-pythonの構築
llama-cpp-pythonをDockerで構築する方法を紹介します。
-
まず、使用したいモデルを任意のディレクトリに配置します。ただし、gguf形式であることに注意してください。
-
次に、前項目で紹介したように、複数モデルを扱うためのJSONファイルを作成し、モデルと同じディレクトリに配置してください。 今回は例として、「ELYZA Japanese LLaMA 2 7b」、「ELYZA Japanese CodeLLaMA 7b」、「LLaMA 2 13b」の3つのモデルを使用します。
{
"host": "0.0.0.0",
"port": 8000,
"models": [
{
"model": "/models/ELYZA-japanese-Llama-2-7b-fast-instruct-q5_K_M.gguf",
"model_alias": "ELYZA-Llama-2-7b-fast",
"chat_format": "llama-2",
"n_gpu_layers": -1,
"offload_kqv": true,
"n_threads": 12,
"n_batch": 512,
"n_ctx": 2048
},
{
"model": "/models/ELYZA-japanese-CodeLlama-7b-instruct-q4_K_S.gguf",
"model_alias": "ELYZA-CodeLlama-7b",
"chat_format": "llama-2",
"n_gpu_layers": -1,
"offload_kqv": true,
"n_threads": 12,
"n_batch": 512,
"n_ctx": 2048
},
{
"model": "/models/llama-2-13b.Q2_K.gguf",
"model_alias": "llama-2-13b",
"chat_format": "llama-2",
"n_gpu_layers": -1,
"offload_kqv": true,
"n_threads": 12,
"n_batch": 512,
"n_ctx": 2048
}
]
}- 現時点でのディレクトリは以下のようになります。
PS C:\Users\mune0\llama-cpp-python\models> ls
ディレクトリ: C:\Users\mune0\llama-cpp-python\models
Mode LastWriteTime Length Name
---- ------------- ------ ----
-a---- 2024/03/10 2:23 3856831168 ELYZA-japanese-CodeLlama-7b-instruct-q4_K_S.gguf
-a---- 2024/03/11 10:51 4863972096 ELYZA-japanese-Llama-2-7b-fast-instruct-q5_K_M.gguf
-a---- 2024/03/11 9:53 5429348224 llama-2-13b.Q2_K.gguf
-a---- 2024/03/11 11:54 1083 model_config.json
PS C:\Users\mune0\llama-cpp-python\models>- 以下のコマンドを使用して、Dockerでlcp[server]を構築します。 今回は公式でGHCRにDockerイメージがアップロードサイトされているため、これを使用します。
docker run --rm -it -p 8000:8000 -v <モデルが配置されているディレクトリ>:/models -e CONFIG_FILE=/models/model_config.json ghcr.io/abetlen/llama-cpp-python:latest- 起動すると、以下のように表示されます。
INFO: Uvicorn running on http://0.0.0.0:8000 (Press CTRL+C to quit)と表示されれば成功です。
Try increasing RLIMIT_MEMLOCK ('ulimit -l' as root).
.................................................................................................
llama_new_context_with_model: n_ctx = 2048
llama_new_context_with_model: freq_base = 10000.0
llama_new_context_with_model: freq_scale = 1
llama_kv_cache_init: CPU KV buffer size = 1024.00 MiB
llama_new_context_with_model: KV self size = 1024.00 MiB, K (f16): 512.00 MiB, V (f16): 512.00 MiB
llama_new_context_with_model: CPU input buffer size = 13.02 MiB
llama_new_context_with_model: CPU compute buffer size = 160.00 MiB
llama_new_context_with_model: graph splits (measure): 1
AVX = 1 | AVX_VNNI = 0 | AVX2 = 1 | AVX512 = 0 | AVX512_VBMI = 0 | AVX512_VNNI = 0 | FMA = 1 | NEON = 0 | ARM_FMA = 0 | F16C = 1 | FP16_VA = 0 | WASM_SIMD = 0 | BLAS = 0 | SSE3 = 1 | SSSE3 = 1 | VSX = 0 | MATMUL_INT8 = 0 |
Model metadata: {'general.file_type': '17', 'tokenizer.ggml.unknown_token_id': '0', 'tokenizer.ggml.eos_token_id': '2', 'general.architecture': 'llama', 'llama.context_length': '4096', 'general.name': 'ELYZA-japanese-Llama-2-7b-fast-instruct', 'general.source.huggingface.repository': 'elyza/ELYZA-japanese-Llama-2-7b-fast-instruct', 'llama.embedding_length': '4096', 'llama.tensor_data_layout': 'Meta AI original pth', 'llama.feed_forward_length': '11008', 'llama.attention.layer_norm_rms_epsilon': '0.000001', 'llama.rope.dimension_count': '128', 'tokenizer.ggml.bos_token_id': '1', 'llama.attention.head_count': '32', 'llama.block_count': '32', 'llama.attention.head_count_kv': '32', 'general.quantization_version': '2', 'tokenizer.ggml.model': 'llama'}
INFO: Started server process [221]
INFO: Waiting for application startup.
INFO: Application startup complete.
INFO: Uvicorn running on http://0.0.0.0:8000 (Press CTRL+C to quit)- ブラウザからlcp[server]へアクセスします。以下のURLでアクセスすると、Swaggerの画面が起動します。
http://<IPアドレス>:8000/docs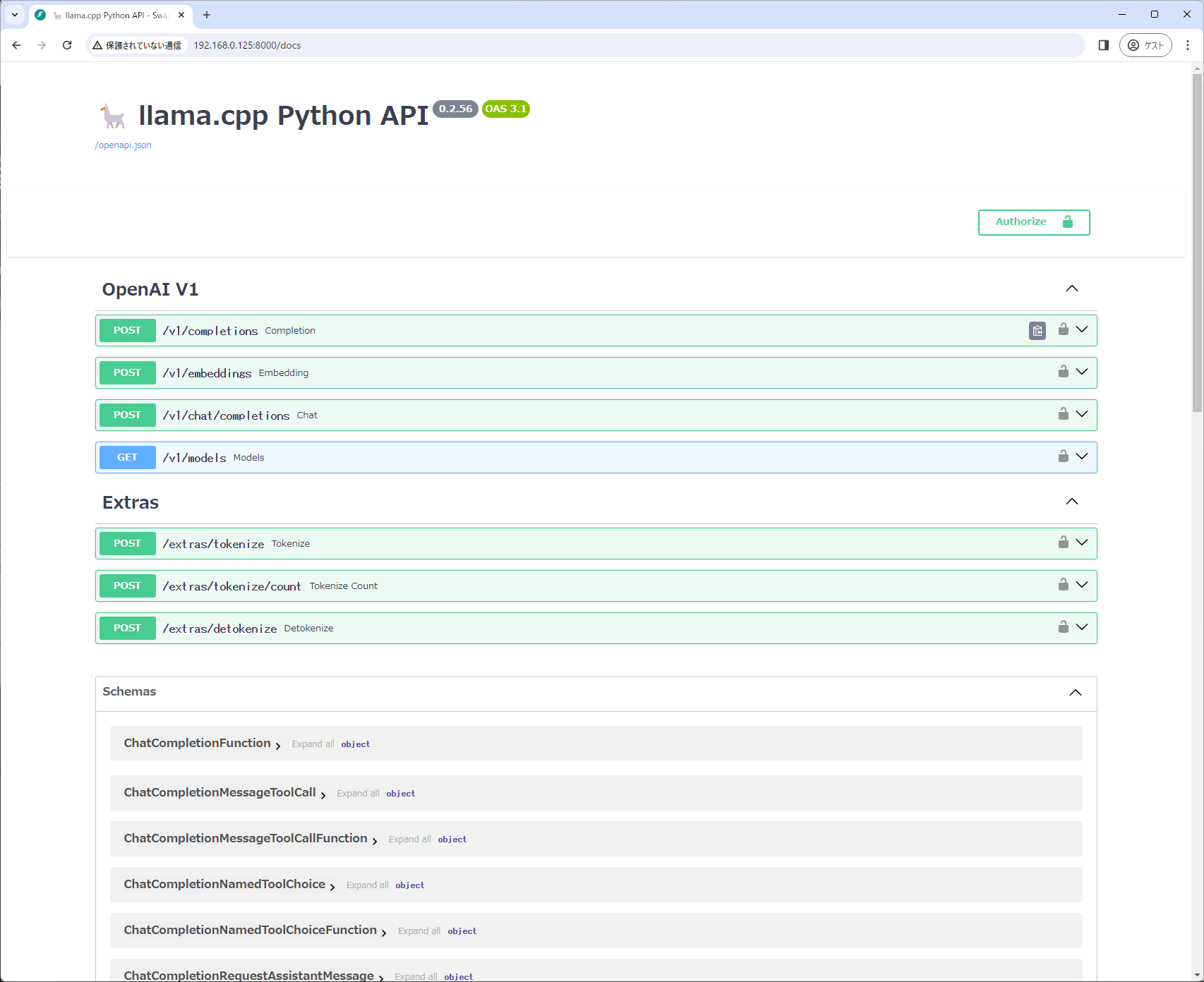
- 複数モデルの反映を確認します。OpenAI V1内の「/v1/models」を開き、「try it out」→「Execute」をクリックします。 「Responese Body」に設定したモデルが表示されていれば成功です。
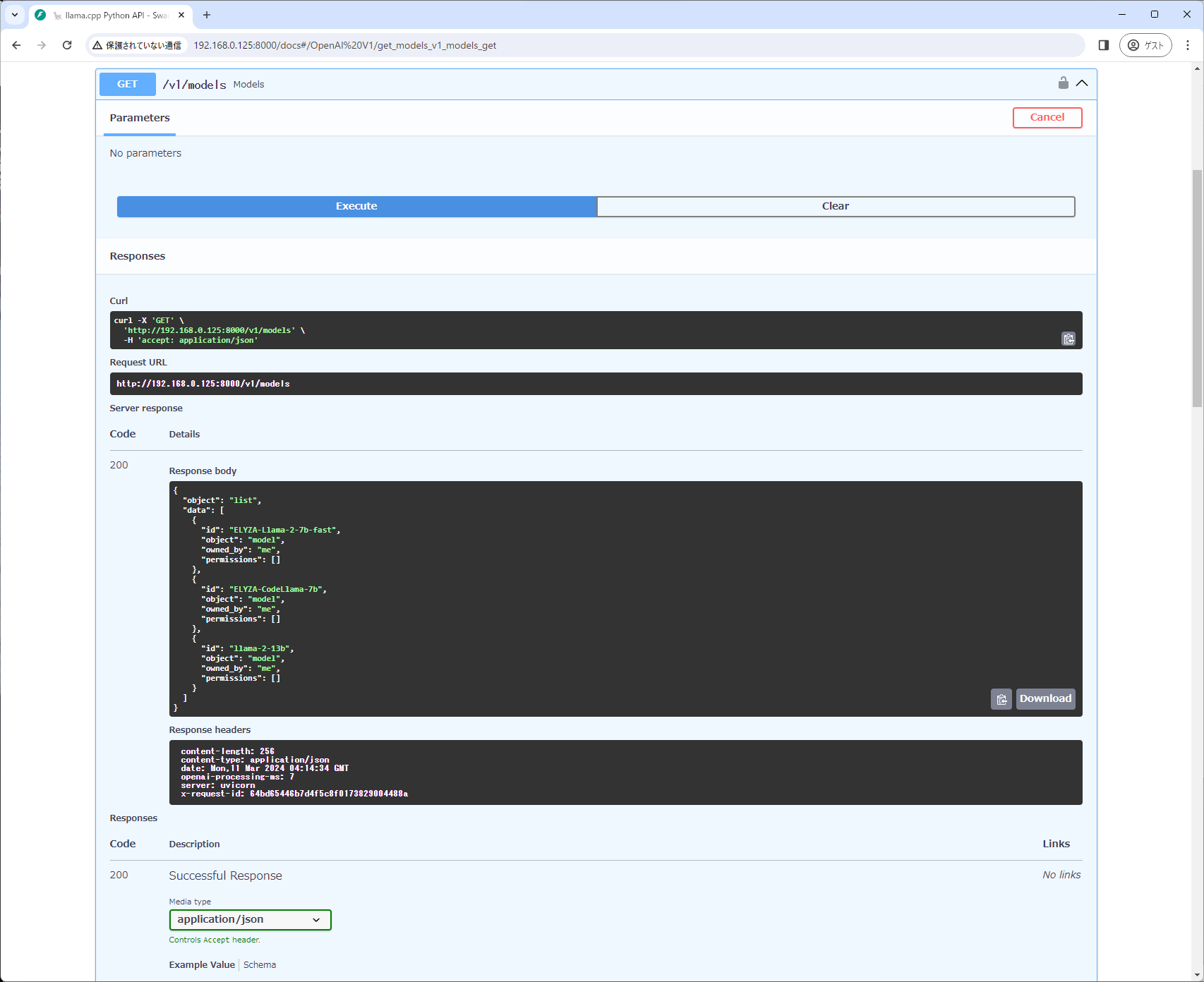
{
"object": "list",
"data": [
{
"id": "ELYZA-Llama-2-7b-fast",
"object": "model",
"owned_by": "me",
"permissions": []
},
{
"id": "ELYZA-CodeLlama-7b",
"object": "model",
"owned_by": "me",
"permissions": []
},
{
"id": "llama-2-13b",
"object": "model",
"owned_by": "me",
"permissions": []
}
]
}- これでllama-cpp-pythonでの作業は終了です。 モデルを追加する場合はmodelsディレクトリにモデルをを追加し、config_fileを書き換え、Dockerを起動し直してください。
Chatbot UIのローカルLLMへの対応
Chatbot UIをローカルLLMで使用する場合、一部コードの書き替えが必要になります。その内容を紹介します。 実際に作業する内容は次項目になります。本項目は飛ばしていただいて構いません。
Chatbot UIは本来、OpenAIのモデルのみサポートしており、ローカルLLMの動作は想定されておりません。そのため、OpenAI API互換のあるローカルLLMサーバを構築しても一部、機能が使用できません。
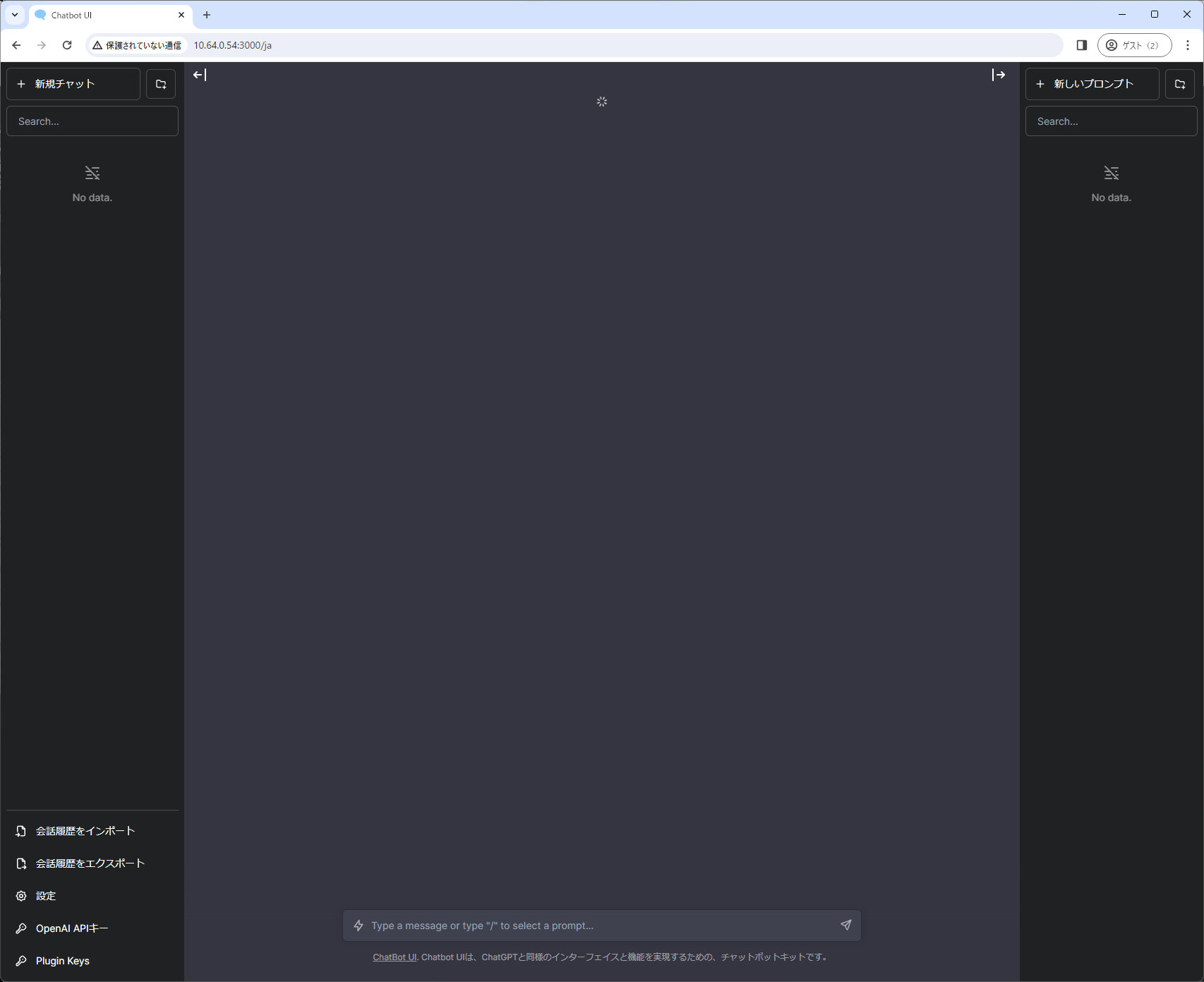
※モデルの選択画面が出ず、永遠とロードを繰り返してしまう。
そこで、pages/api/models.ts内のコードを書き換え、任意のモデルを扱えるように変更します。
変更前
const models: OpenAIModel[] = json.data
.map((model: any) => {
for (const [key, value] of Object.entries(OpenAIModelID)) {
if (value === model.id) {
return {
id: model.id,
name: OpenAIModels[value].name,
};
}
}
})
.filter(Boolean);変更後
const models = json.data.map((model: any) => ({
id: model.id,
name: model.id,
}));本来のコードでは以下で定義されたOpenAIのモデルと一致したもののみ、データを受け渡す仕様となっております。ここに新規に追加するローカルLLMの情報を記述する方法もありますが、拡張性に欠けるため、上記のようなコードの修正を行いました。
export interface OpenAIModel {
id: string;
name: string;
maxLength: number; // maximum length of a message
tokenLimit: number;
}
export enum OpenAIModelID {
GPT_3_5 = 'gpt-3.5-turbo',
GPT_4 = 'gpt-4',
}
// in case the `DEFAULT_MODEL` environment variable is not set or set to an unsupported model
export const fallbackModelID = OpenAIModelID.GPT_3_5;
export const OpenAIModels: Record<OpenAIModelID, OpenAIModel> = {
[OpenAIModelID.GPT_3_5]: {
id: OpenAIModelID.GPT_3_5,
name: 'GPT-3.5',
maxLength: 12000,
tokenLimit: 4000,
},
[OpenAIModelID.GPT_4]: {
id: OpenAIModelID.GPT_4,
name: 'GPT-4',
maxLength: 24000,
tokenLimit: 8000,
},
};本修正版Chatbot UIは私のリポジトリにフォークしてあります。また、以降の手順では修正されたバージョンを使用しますのでご承知くださ https://github.com/mckaywrigley/chatbot-ui/compare/legacy...MuNeNICK:chatbot-ui-local-llm:legacy
Chatbot UIの構築
Chatbot UIを構築する方法を紹介します。
先述した通り、本家ではなく、ローカルLLMに対応させたバージョンを使用いたしますのでご了承ください。
また、本家ではv2がリリースされていますが、Supabaseの利用が面倒なため、legacy版での内容となります。
- 以下のコマンドを実行し、DockerでChatbot UIを構築します。
docker run -e OPENAI_API_HOST=<lcp[server]のIPアドレス:ポート> -e OPENAI_API_KEY=fake_key -e DEFAULT_SYSTEM_PROMPT="あなたは優秀なアシスタントです" -p 3000:3000 munenick/chatbot-ui-local-llm- 以下のURLでWebUIにアクセスします。
http://<Chatbot UIのIPアドレス>:3000
-
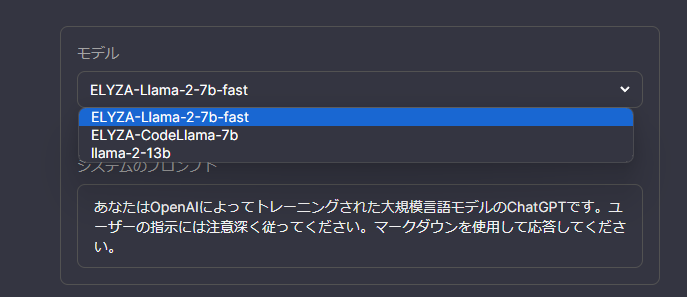
モデルから自身が構築したものが選択できれば成功です。
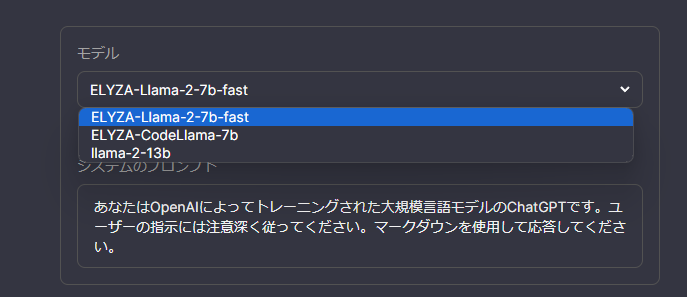
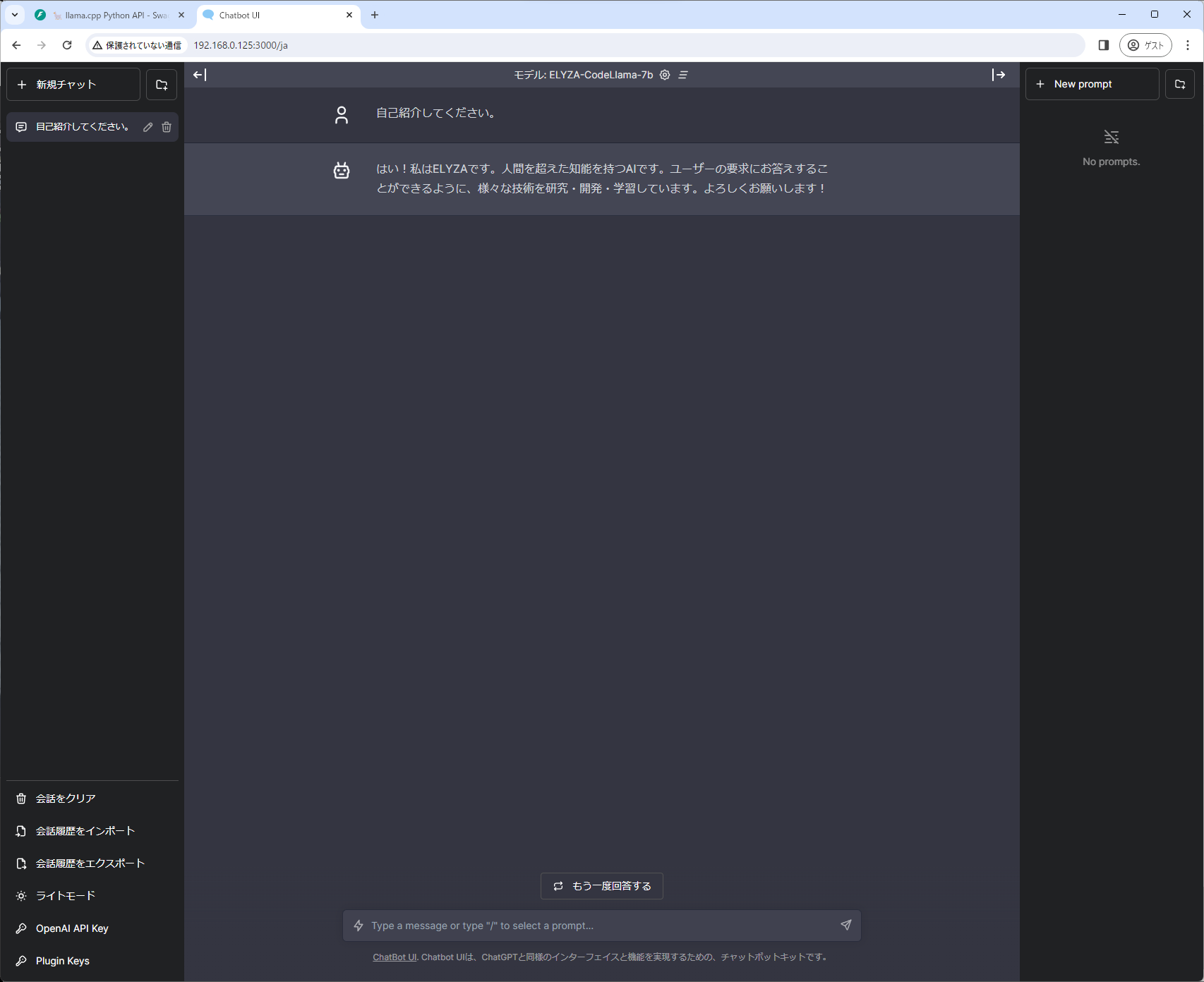
-
あとは通常通り、チャットが使用できるはずです。(人間を超えた知能…)
Docker-Composeを用いた構築
- docker-composeを使用して構築する場合は以下を使用することができます。
version: '3.8'
services:
chatbot-ui:
image: munenick/chatbot-ui-local-llm
ports:
- "3000:3000"
environment:
OPENAI_API_HOST: "http://llama-cpp-python:8000"
OPENAI_API_KEY: "fake_key"
DEFAULT_SYSTEM_PROMPT: "あなたは優秀なアシスタントです"
llama-cpp-python:
image: ghcr.io/abetlen/llama-cpp-python:latest
ports:
- "8000:8000"
volumes:
- "<モデルが配置されているディレクトリ>:/models"
environment:
CONFIG_FILE: "/models/model_config.json"- 以下のコマンドを使用して、docker-composeを起動してください。
docker compose up -d- 以下のURLでWebUIにアクセスします。
http://<Chatbot UIのIPアドレス>:3000おわりに
今回はllama-cpp-pythonとChatbot UIを用いてWebUIから複数のローカルLLMを扱う方法を紹介しました。 Chatbot UIは非常によくできたUIでしたが、ローカルLLMを扱う場合に一部機能が動作しなかったため、今回私の方でコード修正を行いました。
llama-cpp-pythonで複数のモデルを切り替えるのがめんどくさい方やローカルLLMでWebUIがほしい方はぜひ参考にしてください。