はじめに
VMware vSphere環境ではTanzu Kubernetes Grid(通称: TKG)を使用することで簡単にKubernetes環境を構築することができます。本記事で紹介するTKGはStandalone版であり、マルチクラウドに対応可能なTKGmです。また、NSX ALBはEssentialsライセンスを使用していきます。本記事では事前準備およびBootStrapマシンの構築方法を記述しています。本記事ではTanzu Kubernetes Gridの構築として、ManagementクラスタおよびWorkloadクラスタの構築手順を記述しています。
前回
今回はNSX ALBの構築、事前準備、BootStrapマシンの構築がしてあることを前提に進んでいきます。構築がまだな方は以下の記事を参考に事前準備およびBootStrapマシンの構築をよろしくお願いします。
https://www.munenick.me/blog/tkg-nsx-alb-02
環境
| 環境 |
|---|
| VMware ESXi 8 |
| VMware vCenter 8 |
| Tanzu Kubernetes Grid 2.1.1 |
| NSX Advanced Load Balancer 22.1.3 |
前提条件
- VMware ESXiの構築及びvCenterを使用してDatacenterの管理ができていること
- 2つ以上のVLAN環境が構築できていること
- 本環境ではマネジメントネットワーク:VM Network(VLAN0)とKubernetes用ネットワーク:VLAN100(VLAN100)を用意しています。
- 十分なリソースのあるサーバ、ストレージ
- NSX ALBでCPU:8, RAM:24GB, ROM:128GB使用します。
- 要件によりますが、デプロイするKubernetesノードでもCPU:2, RAM:8GB, ROM:40GBの仮想マシンが4~12個デプロイされます。
Managementクラスタの構築
デプロイ用WebUIの起動
デプロイにはyamlを記述する方法とWebUIを使用する方法があります。今回、Managementクラスタを作成する際にはWebUIを使用します。
-
TeratermなどでBootStrapマシンにSSH接続してください。また、前回作成した一般ユーザでログインしてください。
-
以下のコマンドを入力し、WebUIを起動してください。
MuNeNiCK [ ~ ]$ tanzu management-cluster create --ui --bind=0.0.0.0:8080 --browser=none
Validating the pre-requisites...
Serving kickstart UI at http://[::]:8080- ブラウザを起動し、「https://BootStrapマシンのIPアドレス:8080」にアクセスしてください。
Managementクラスタのデプロイ
デプロイ先の選択
- WebUIにアクセスしたら、まずデプロイ先を選択することができます。今回は「VMware vSphere」の「Deploy」をクリックしてください。
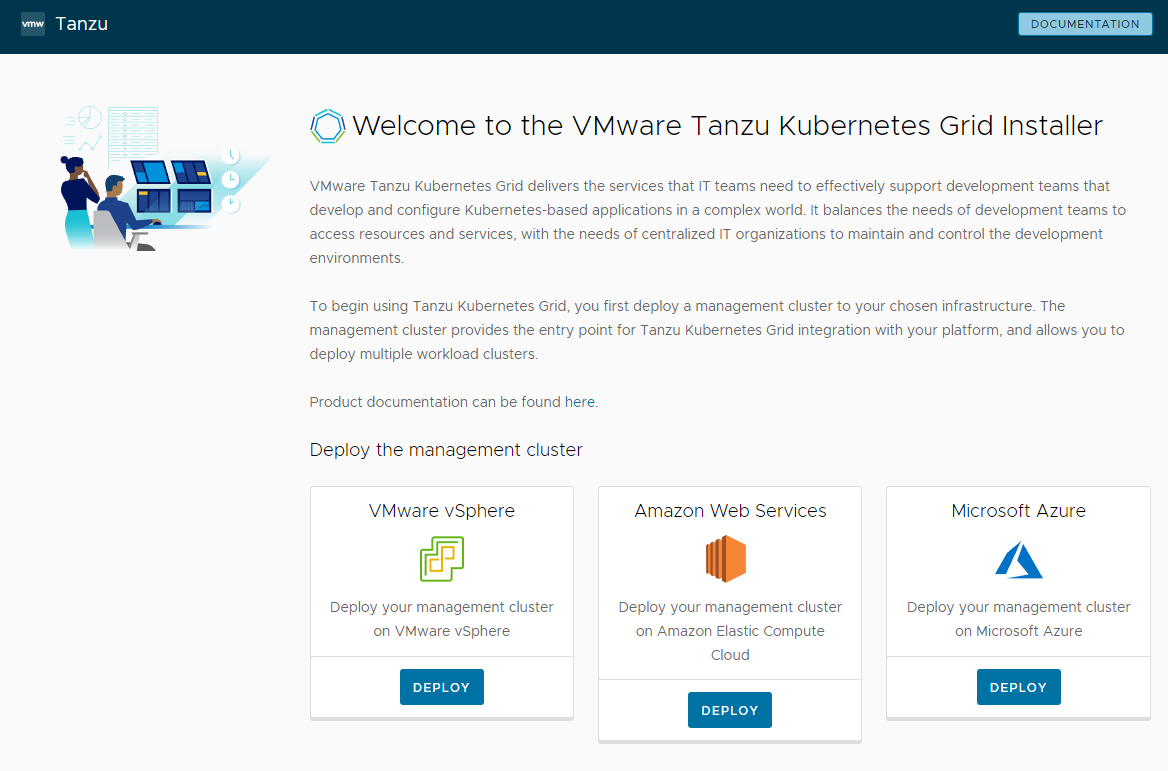
IaaS Providerの設定
-
以下の項目を設定し、「CONNECT」をクリックし、vCenter Serverに接続します。
- VCENTER SERVER: vCenter ServerのIPアドレスまたはFQDNを指定してください。
- USERNAME: vCenterのadministratorアカウント名を入力してください。
- PASSWORD: vCenterのadministratorのパスワードを入力してください。
- SSL THUMBPRINT VERIFICATION: vCenterが自己証明書の場合、チェックを入れてください。
-
デプロイ方法の指定ができます。「CONFIGURE VSPHERE WITH TANZU」はTKGsと呼ばれており、vSphere環境に組み込む形でデプロイされます。「DEPLOY TKG MANAGEMENT CLUSTER」はTKGmと呼ばれおり、マルチクラウドに対応したスタンドアロンクラスタを構築します。今回は「DEPLOY TKG MANAGEMENT CLUSTER」をクリックし、TKGmを構築します。
-
vCenterに接続すると追加で以下の項目を設定できるようになります。
- DATACENTER: クラスタをデプロイするデータセンタを指定してください。
- SSH PUBLIC KEY: 前回記事でBootStrapマシンのセットアップ時に作成したSSH鍵を指定します。
これらの設定を終えたら「NEXT」をクリックしてください。
Cluster Settingsの設定
- 以下の項目を設定します。
-
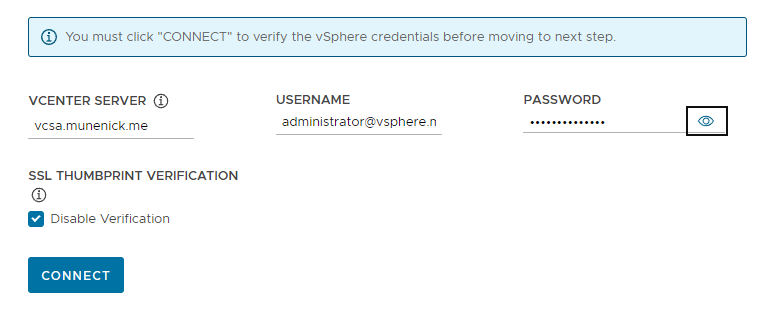
デプロイタイプ: デプロイタイプは「Development」と「Production」の2つから選択することができます。名前の通り、開発環境では「Development」、本番環境では高可用性の「Production」を指定するといいでしょう。今回は「Development」を選択します。
- Development: 1つのcontrol-planeノードと1つのworkerノード、計2つの仮想マシンが作成されます。
- Production: 3つのcontrol-planeノードと3つのworkerノード、計6つの仮想マシンが作成されます。
-
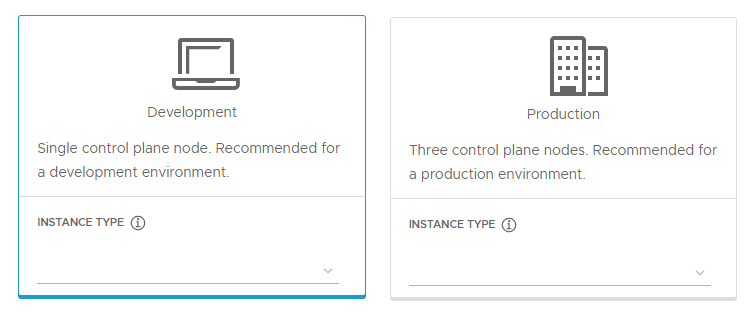
INSTANCE TYPE: Managementクラスタでデプロイさるノードのスペックを「small」、「medium」、「large」、「extra-large」の4つから選択することができます。デプロイタイプで指定した仮想マシンの台数分選択したINSTANCE TYPEのスペックの仮想マシンがデプロイされます。今回は「medium」を選択します。
- small: cpu: 2, ram: 4GB, disk: 20GB
- medium: cpu: 2, ram: 8GB, disk: 40GB
- large: cpu: 4, ram: 16GB, disk: 20GB
- extra-large: cpu: 2, ram: 4GB, disk: 20GB
-
MANAGEMENT CLUSTER NAME: デプロイするManagementクラスタの名前を指定します。今回は「tkg21mc01」としました。
-
MACHINE HEALTH CHECKS: デプロイされたノードのヘルスチェックを行います。
-
CONTROL PLANE ENDPOINT PROVIDER: 「kube-vip」と「NSX Advanced Load Balancer」の2つから選択することができます。今回は「NSX Advanced Load Balancer」を選択します。
-
CONTROL PLANE ENDPOINT: control-planeノードのVIPアドレスを指定することができます。今回は指定しません。
-
WORKER NODE INSTANCE TYPE: Workloadクラスタでデプロイされるノードのスペックを 設定します。項目はINSTANCE TYPEと同様です
-
ACTIVATE AUDIT LOGGING: 監査ログを有効化します。
-
今回は以下のような設定になりました。これはあくまで1例であり、ご自身の環境や要件によって変更してください。
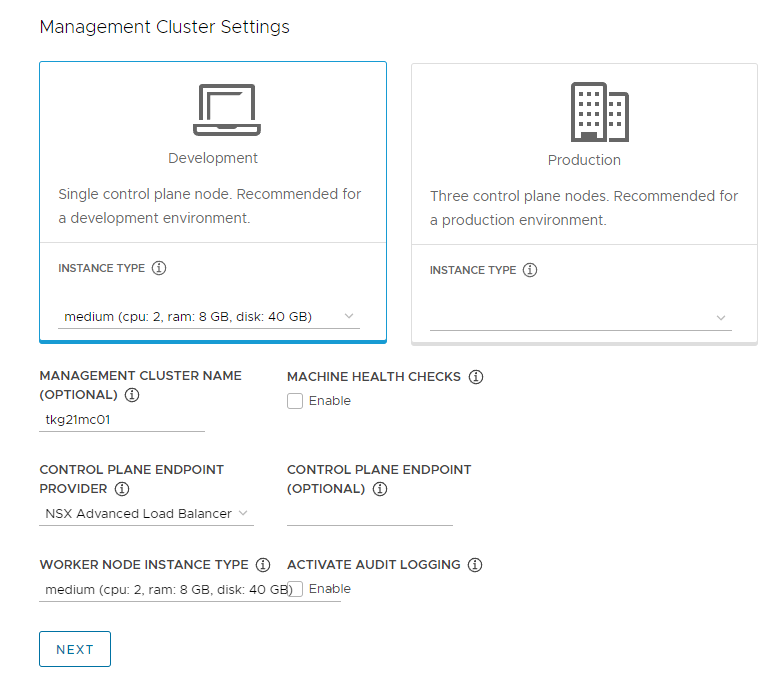
すべての設定を終えたら「NEXT」をクリックしてください。
VMware NSX Advanced Load Balancerの設定
-
以下の項目を設定し、「VERIFY CREDENTIALS」をクリックすることで、NSX ALBに接続します。
- CONTROLLER HOST: NSX ALBのIPアドレスまたはFQDNを指定してください。
- USERNAME: NSX ALBにログインするためのアカウント名を指定してください。デフォルトの場合、「admin」になります。
- PASSWORD: アカウントに対するパスワードを指定してください。
- CONTROLLER CERTIFICATE AUTHORITY: NSX ALB構築時の証明書の取得にて取得した証明書をペーストします。
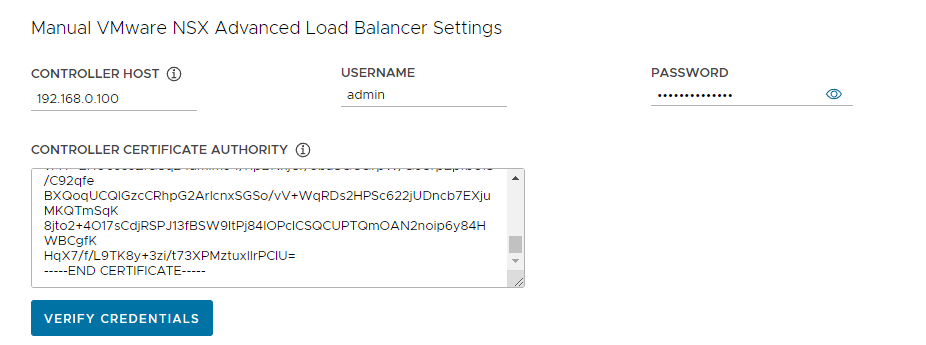
-
NSX ALBに接続すると追加で以下の項目を設定することができます。
- CLOUD NAME: 「Default-Cloud」を指定してください。
- Workload Cluster: Workloadクラスタの設定になります。
- SERVICE ENGINE GROUP NAME: 「Default-Group」を指定してください。
- WORKLOAD CLUSTER - DATA PLANE VIP NETWORK NAME: Kubernetes用ネットワークを指定してください。
- WORKLOAD CLUSTER - CONTROL PLANE VIP NETWORK NAME: Kubernetes用ネットワークを指定してください。
- WORKLOAD CLUSTER - DATA PLANE VIP NETWORK CIDR: Kubernetes用ネットワークアドレスを入力してください。
- WORKLOAD CLUSTER - CONTROL PLANE VIP NETWORK CIDR: Kubernetes用ネットワークアドレスを入力してください。
- Management Cluster: Managementクラスタの設定になります。基本的にはWorkload Clusterの設定と同じになります。
- MANAGEMENT CLUSTER - SERVICE ENGINE GROUP NAME: 「Default-Group」を指定してください。
- MANAGEMENT CLUSTER - DATA PLANE VIP NETWORK NAME: Kubernetes用ネットワークを指定してください。
- MANAGEMENT CLUSTER - CONTROL PLANE VIP NETWORK: Kubernetes用ネットワークを指定してください。
- MANAGEMENT CLUSTER - DATA PLANE VIP NETWORK CIDR: Kubernetes用ネットワークアドレスを入力してください。
- MANAGEMENT CLUSTER - CONTROL PLANE VIP NETWORK CIDR: Kubernetes用ネットワークアドレスを入力してください。
- CLUSTER LABELS: クラスタにラベルを付与することができます。
今回の設定は以下のようになります。この設定は1例であり、ネットワーク設計やNSX ALBの設定が異なる場合はご自身の環境に合わせて設定をしてください。
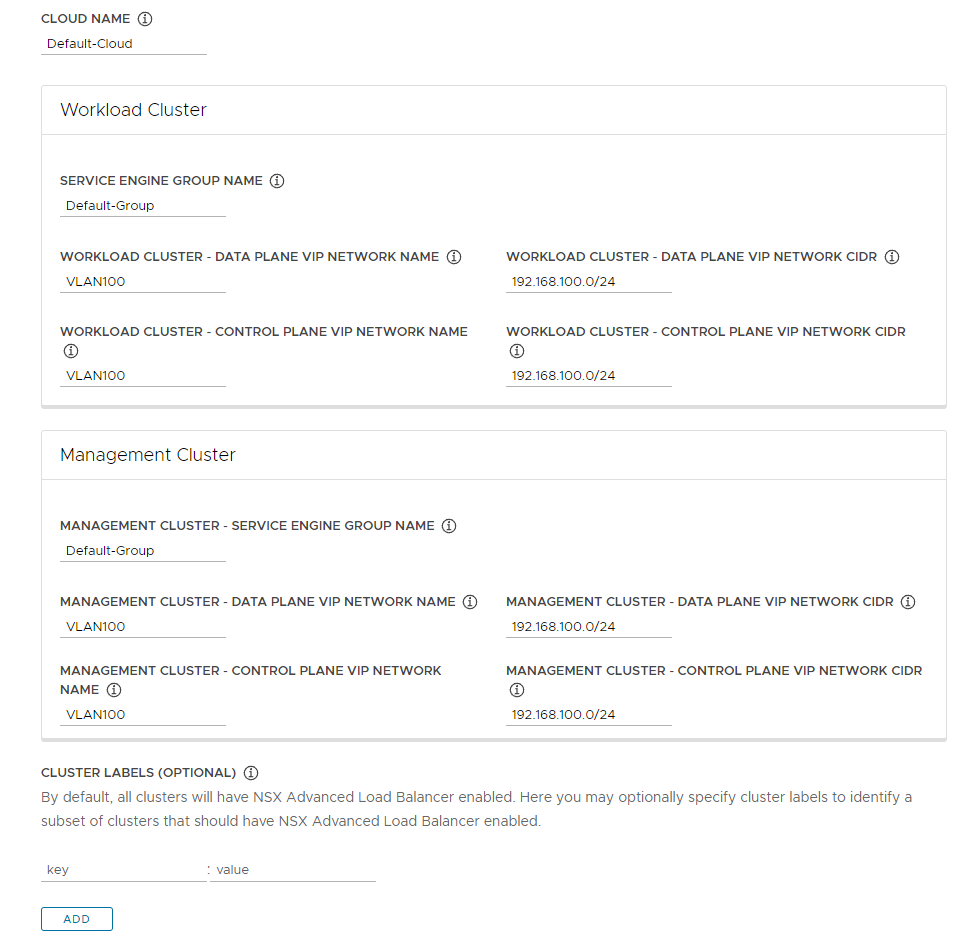
すべての設定を終えたら「NEXT」をクリックしてください。
Metadataの設定
ここではManagementクラスタのメタデータを指定することができます。今回は設定しません。
設定を終えたら「NEXT」をクリックしてください。
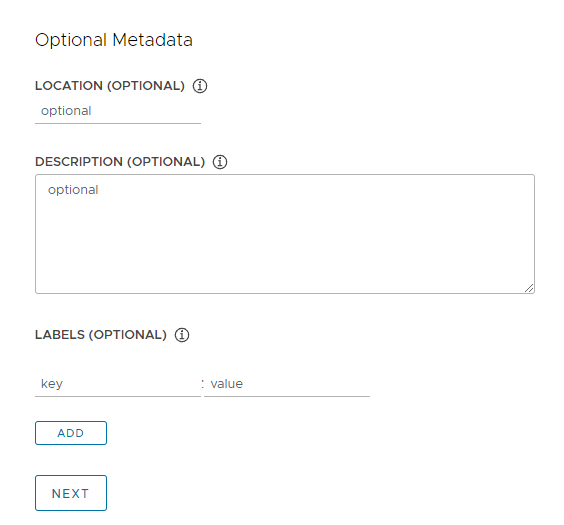
Resourcesの設定
- 以下の項目を設定します。
- VM FOLDER: Managementクラスタをデプロイするフォルダを選択します。今回の場合、事前準備にて作成したフォルダである「/Datacenter/vm/TKG/Management」になります。
- DATASTORE: Managementクラスタのノードとしてデプロイされる仮想マシンの保存先データストアを指定してください。
- CLUSTERS, HOSTS, AND RESOURCE POOLS: Managementクラスタのノードとしてデプロイされる仮想マシンの作成先クラスタまたはホスト、リソースプールを指定してください。
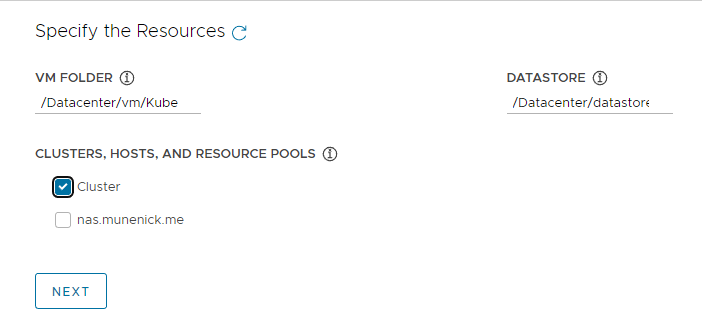
すべての設定を終えたら「NEXT」をクリックしてください。
Kubernetes Networkの設定
- 以下の項目を設定します。
- NETWORK NAME: Managementクラスタのノードとしてデプロイされる仮想マシンに割り当てられるネットワークを指定してください。Kubernetes用ネットワークを指定しても問題ありません。
- CLUSTER SERVICE CIDR: クラスタのサービスで使用されるネットワークアドレスです。デフォルトのままで構いません。
- CLUSTER POD CIDR: クラスタのPodで使用されるネットワークアドレスです。デフォルトのままで構いません。
- Proxy Settings: ネットワーク接続にプロキシが必要な場合は設定してください。今回は設定しません。
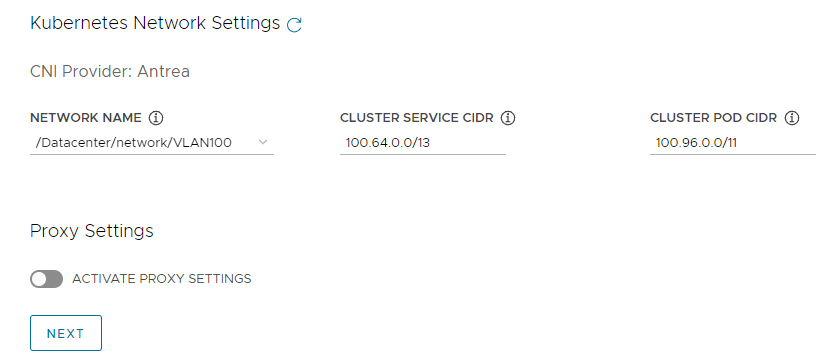
すべての設定を終えたら「NEXT」をクリックしてください。
Identity Managementの設定
- 必要に応じてOIDCやLDAPを使用した認証管理を行います。今回は使用しないので無効のまま進みます。
OS Imageの設定
- TKRの指定を行います。TKRが正常にテンプレート化されている場合、プルダウンメニューに表示されます。今回はPhoton v3を指定します。
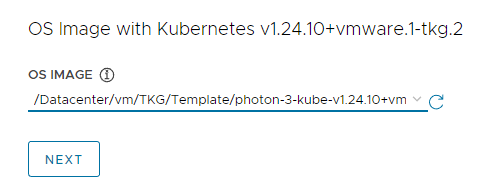
設定を終えたら「NEXT」をクリックしてください。
CEIP Agreementの設定
- 情報提供を行うかの確認です。今回はオフにしています。

設定の確認
-
必要な設定を終えている場合、各項目の横に緑色のチェックマークがつき、「REVIEW CONFIGURATION」が押せるようになっているはずです。「REVIEW CONFIGURATION」をクリックしてください。
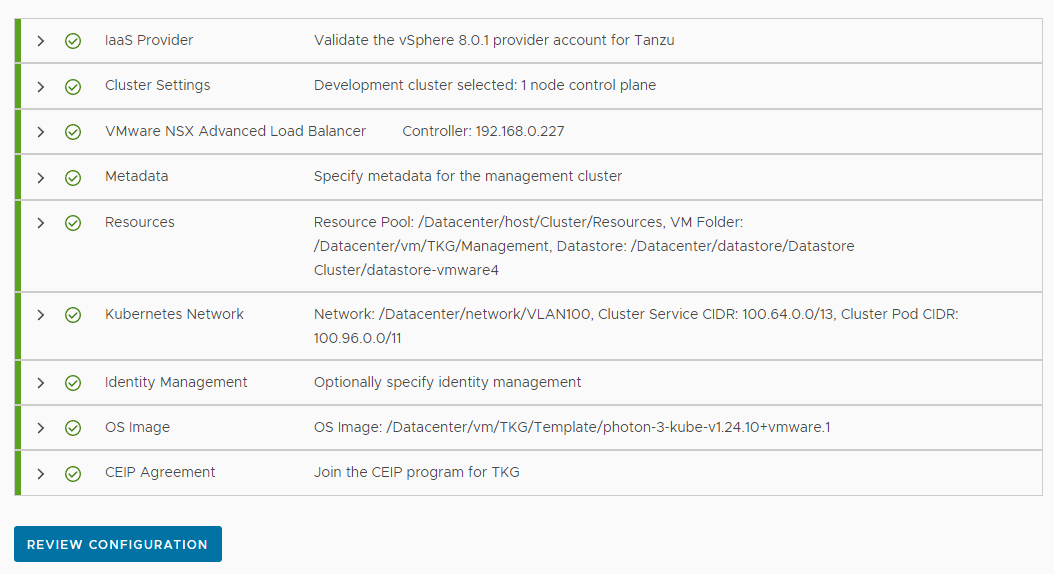
-
「Tanzu Kubernetes Grid - Confirm Settings」にて設定の確認を行うことができます。設定が正しいことを確認したら「DEPLOY MANAGEMEMT CLUSTER」をクリックシてください。やり直しがある場合は「EDIT CONFIGURATION」をクリックしてください。また、今回設定した内容をyamlで保存するには、「EXPORT CONFIGURATION」をクリックしてください。
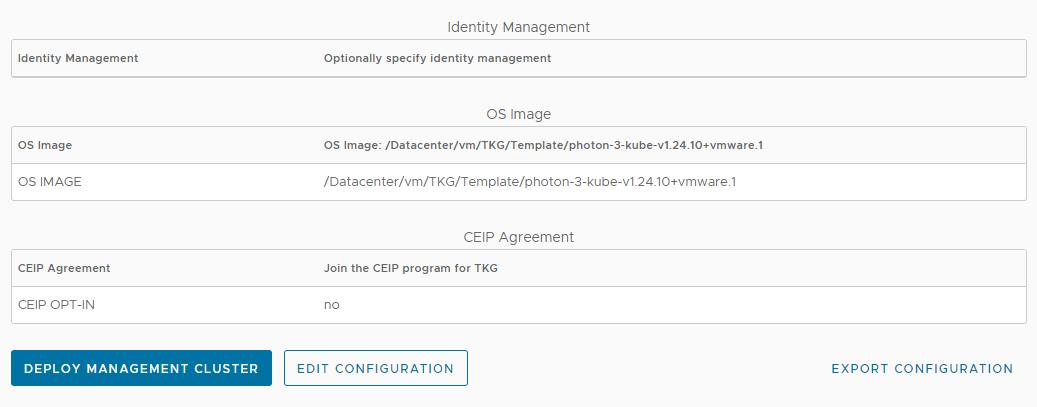
デプロイの待機
環境のデプロイが始まるとWebUIおよびSSH上のBootStrapマシンにログとして表示されます。項目が完了するまでお待ち下さい。環境や設定によって異なりますが、50分程度デプロイにかかることもあります。
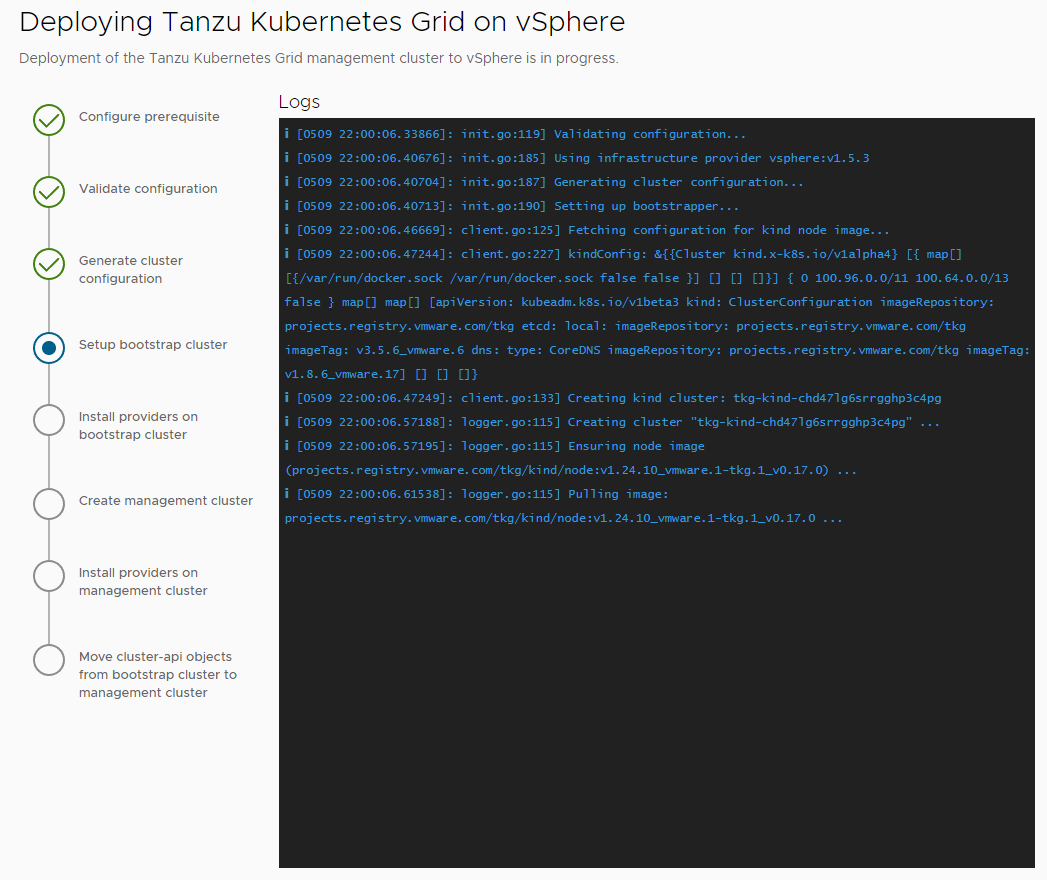
また、WebUIの下部にはデプロイの作業をCUI上で実行するためのコマンドが記述されています。デプロイに失敗した際の再試行等で使用するのでメモを取っておくといいでしょう。

クラスタのデプロイに失敗した場合
クラスタのデプロイに失敗した場合の手順を紹介します。
今回はStart creating management cluster…のプロセスで失敗したようです。
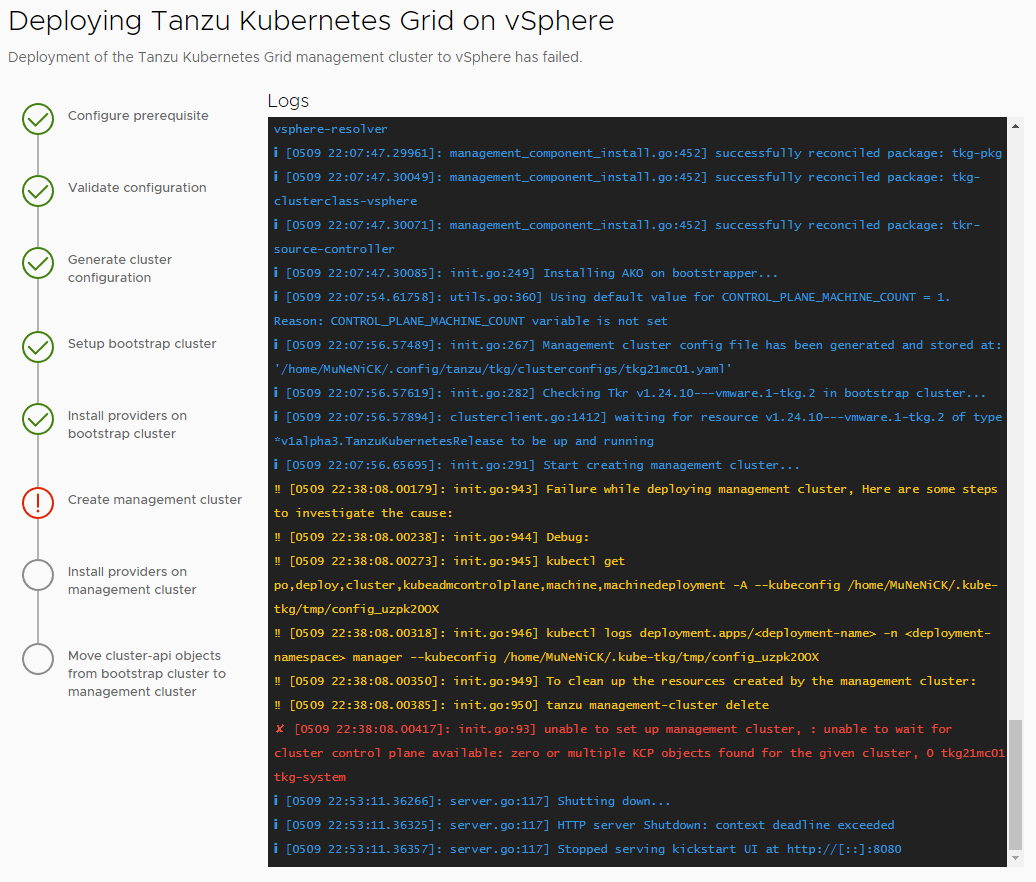
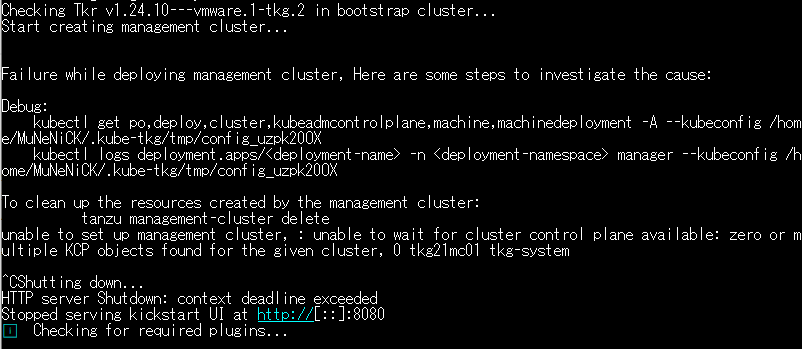
- 原因の特定を行うには、エラーログにある「debug」以下のコマンドを実行します。今回の場合は以下のようになります。
MuNeNiCK [ ~ ]$ kubectl get po,deploy,cluster,kubeadmcontrolplane,machine,machinedeployment -A --kubeconfig /home/MuNeNiCK/.kube-tkg/tmp/config_uzpk20OX
MuNeNiCK [ ~ ]$ kubectl logs deployment.apps/<deployment-name> -n <deployment-namespace> manager --kubeconfig /home/MuNeNiCK/.kube-tkg/tmp/config_uzpk20OX- 作成されたクラスタの削除を行うために以下のコマンドを実行します。
MuNeNiCK [ ~ ]$ tanzu management-cluster delete -y- WebUIからは再作成は行えないため、デプロイの待機にて取得したコマンドを使用します。今回の場合は以下のコマンドを使用することでクラスタの再作成を行えます。
MuNeNiCK [ ~ ]$ tanzu management-cluster create tkg21mc01 --file /home/MuNeNiCK/.config/tanzu/tkg/clusterconfigs/ii252b9tt1.yaml -v 6- また、クラスタ作成の失敗の原因がタイムアウトな場合、「–timeout 時間」オプションを使用することで、タイムアウトまでの時間を延長させることができます。この時、デフォルトのタイムアウト時間は「30m」となっています。
MuNeNiCK [ ~ ]$ tanzu management-cluster create tkg21mc01 --file /home/MuNeNiCK/.config/tanzu/tkg/clusterconfigs/ii252b9tt1.yaml -v 6 --timeout 60m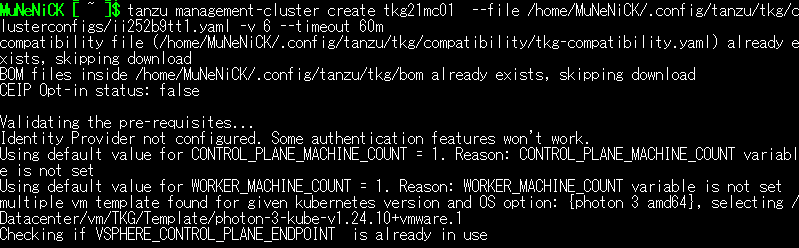
Managementクラスタのデプロイの確認
WebUIまたはBootStrapマシンのログにて成功の旨が表示されていればデプロイの完了です。
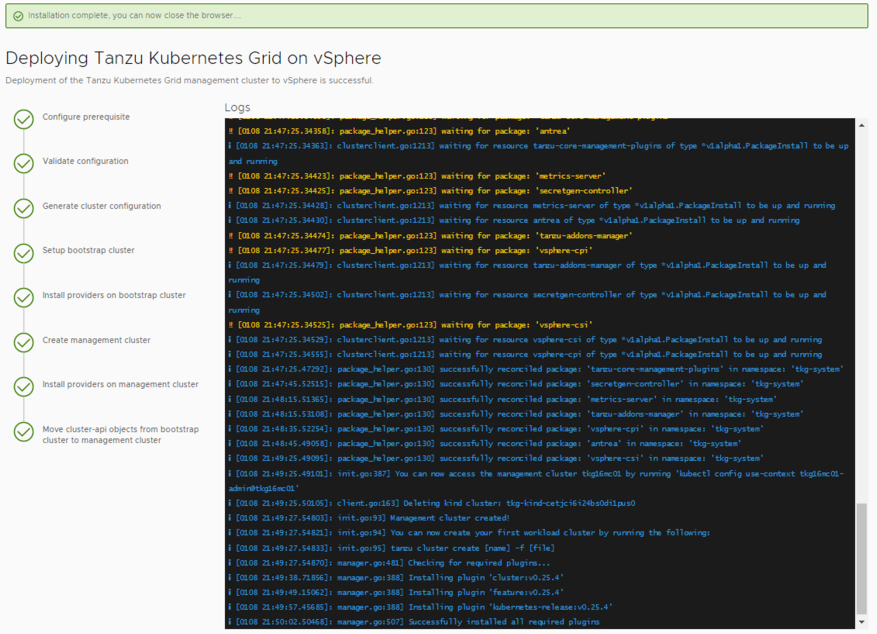
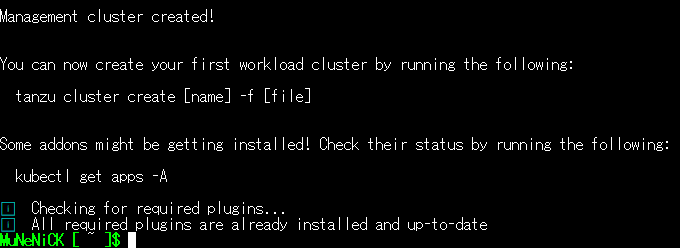
kubectlを用いたデプロイの確認
BootStrapマシンのログにあるように以下のコマンドを実行することでデプロイの確認ができます。
MuNeNiCK [ ~ ]$ kubectl get apps -AvCenterにアクセスして確認
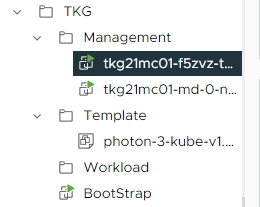
vCenter Serverにログインし、「TKG」→「Management」内に仮想マシンが作成されていることを確認してください。
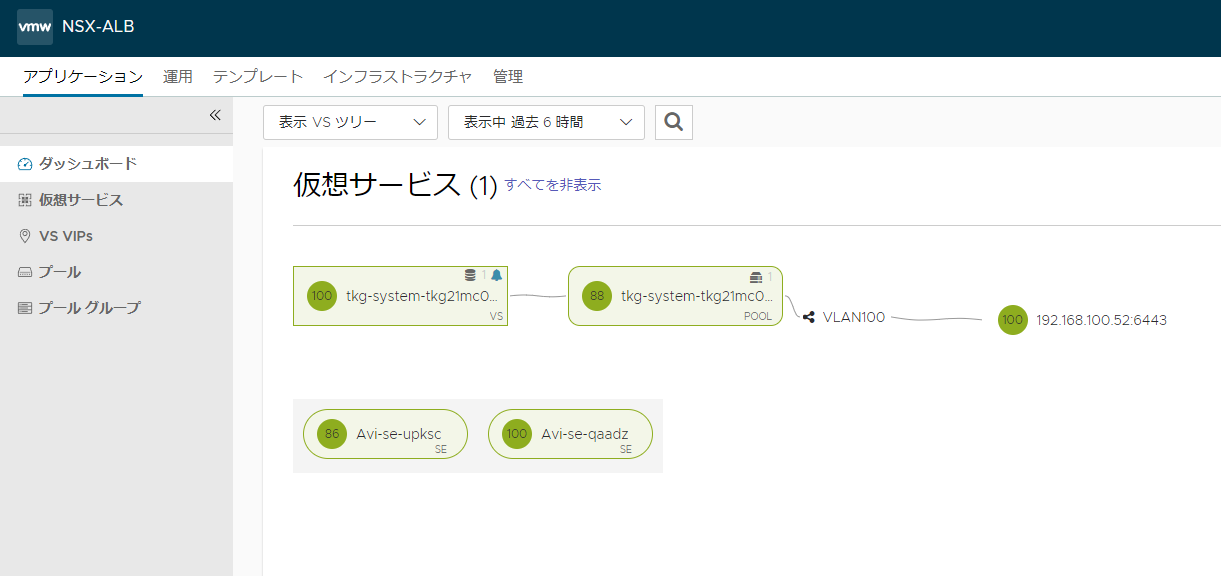
NSX ALBにアクセスして確認
NSX ALBにログインし、「アプリケーション」→「ダッシュボード」にアクセスすることでデプロイを確認できます。画像のように表示するには左上の「VS リスト」を「VS ツリー」に変更してください。
Managementクラスタのyamlの保存
今回作成されたyamlはWorkloadクラスタでも使用します。そのため、以下の手順で保存してください。
- 以下のコマンドを実行し、yamlファイルの存在を確認してください。
MuNeNiCK [ ~ ]$ ls -al $HOME/.config/tanzu/tkg/clusterconfigs/
total 20
drwx------ 2 MuNeNiCK users 4096 May 9 22:07 .
drwx------ 7 MuNeNiCK users 4096 May 9 23:00 ..
-rw------- 1 MuNeNiCK users 4459 May 9 22:00 ii252b9tt1.yaml
-rw------- 1 MuNeNiCK users 3317 May 10 00:13 tkg21mc01.yaml- 以下のコマンドを実行し、yamlファイルをホームディレクトリに保存します。※yamlファイル名は環境によって変わるので適宜読み替えてください。
MuNeNiCK [ ~ ]$ cp $HOME/.config/tanzu/tkg/clusterconfigs/ii252b9tt1.yaml tkg21mc01.yaml- 以下のコマンドを実行し、コピーされたことを確認してください。
MuNeNiCK [ ~ ]$ ls -l $HOME
total 313612
drwxr-x--- 2 MuNeNiCK users 4096 May 9 20:27 bin
drwxr-x--- 3 MuNeNiCK users 4096 Mar 9 09:42 cli
-rwxrwxrwx 1 MuNeNiCK users 46067712 Apr 23 20:34 kubectl-linux-v1.24.10+vmware.1
-rwxrwxrwx 1 root root 275052656 Apr 23 20:34 tanzu-cli-bundle-linux-amd64.tar.gz
-rw------- 1 MuNeNiCK users 4459 May 10 08:49 tkg21mc01.yamlManagementクラスタへの接続
Managementクラスタに接続し、クラスタの管理を行うためいくつかの操作が必要になります。
- まず、以下のコマンドを実行してkubeconfigを取得してください。
MuNeNiCK [ ~ ]$ tanzu mc kubeconfig get --admin
Credentials of cluster 'tkg21mc01' have been saved
You can now access the cluster by running 'kubectl config use-context tkg21mc01-admin@tkg21mc01'- 次にログに出力されている通り、以下のコマンドを実行します。
MuNeNiCK [ ~ ]$ kubectl config use-context tkg21mc01-admin@tkg21mc01
Switched to context "tkg21mc01-admin@tkg21mc01".- 以下のコマンドを実行して現在のコンテキストを確認してください
MuNeNiCK [ ~ ]$ kubectl config get-contexts
CURRENT NAME CLUSTER AUTHINFO NAMESPACE
* tkg21mc01-admin@tkg21mc01 tkg21mc01 tkg21mc01-admin- コンテキストを使用してクラスタのノードを確認します。以下のコマンドを実行してください。
MuNeNiCK [ ~ ]$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
tkg21mc01-f5zvz-tq8wn Ready control-plane 8h v1.24.10+vmware.1
tkg21mc01-md-0-n85gx-6f5bf77dc8-lv58j Ready <none> 8h v1.24.10+vmware.1以上でManagementクラスタの構築および接続が完了となります。
Workloadクラスタの構築
Workloadクラスタ用yamlの作成
- 先程ホームディレクトリにコピーしたManagementクラスタ用のyamlをコピーしてします。以下のコマンドを実行してください。
MuNeNiCK [ ~ ]$ cp tkg21mc01.yaml tkg21wc01.yaml
MuNeNiCK [ ~ ]$ ls -l
total 313620
drwxr-x--- 2 MuNeNiCK users 4096 May 9 20:27 bin
drwxr-x--- 3 MuNeNiCK users 4096 Mar 9 09:42 cli
-rwxrwxrwx 1 MuNeNiCK users 46067712 Apr 23 20:34 kubectl-linux-v1.24.10+vmware.1
-rwxrwxrwx 1 root root 275052656 Apr 23 20:34 tanzu-cli-bundle-linux-amd64.tar.gz
-rw------- 1 MuNeNiCK users 4459 May 10 08:49 tkg21mc01.yaml
-rw------- 1 MuNeNiCK users 4459 May 10 08:57 tkg21wc01.yaml-
viエディタなどで以下の項目を書き換えます。※これはあくまで一例であり、自身の環境に合わせて変更してください。
- CLUSTER_NAME: Workloadクラスタ名に書き換えてください。今回は「tkg21wc01」としています。
- VSPHERE_FOLDER: Workloadクラスタ用フォルダに書き換えてください。今回は「/Datacenter/vm/TKG/Workload」としています。
-
オプション1: 今回はWorkloadクラスタのデプロイタイプを「Development」から「Production」に変更します。以下の項目を書き換えてください。※この設定を適用すると仮想マシンが6台デプロイされます。十分なリソースがある場合のみ実行してください。
- CLUSTER_PLAN: 「dev」から「prod」に変更してください。
-
オプション2: 今回はAutoScalerを使用して、Kubernetesクラスタを自動的に最適なサイズに調整できるようにします。yamlファイルの末尾に以下のコードを記述します。※このAutoScalerはWorkloadクラスタのみ設定可能です。
#! ---------------------------------------------------------------------
#! Autoscaler related configuration
#! ---------------------------------------------------------------------
ENABLE_AUTOSCALER: true
AUTOSCALER_MAX_NODES_TOTAL: "0"
AUTOSCALER_SCALE_DOWN_DELAY_AFTER_ADD: "10m"
AUTOSCALER_SCALE_DOWN_DELAY_AFTER_DELETE: "10s"
AUTOSCALER_SCALE_DOWN_DELAY_AFTER_FAILURE: "3m"
AUTOSCALER_SCALE_DOWN_UNNEEDED_TIME: "10m"
AUTOSCALER_MAX_NODE_PROVISION_TIME: "15m"
# Each min/max pair (0,1,2) corresponds to an availability zone.
# If you have a 'dev' cluster, you only need to fill in the min/max size for '0'.
# If you have a 'prod' cluster, you need to fill in all three pairs.
AUTOSCALER_MIN_SIZE_0: 1
AUTOSCALER_MAX_SIZE_0: 5
AUTOSCALER_MIN_SIZE_1: 1
AUTOSCALER_MAX_SIZE_1: 5
AUTOSCALER_MIN_SIZE_2: 1
AUTOSCALER_MAX_SIZE_2: 5-
ENABLE_AUTOSCALER: 「Autoscaler」を有効化/無効化を決定します。
-
AUTOSCALER_MAX_NODES_TOTAL: control-planeノードとworkerノードの合計の数を制限します。0に指定することで制限を解除することができます。
-
AUTOSCALER_SCALE_DOWN_DELAY_AFTER_ADD: スケール アップ操作後にクラスタ オートスケーラがスケール ダウン スキャンを再開するまで待機する時間です。
-
AUTOSCALER_SCALE_DOWN_DELAY_AFTER_DELETE: ノードの削除後にクラスタ オートスケーラがスケールダウン スキャンを再開するまで待機する時間です。
-
AUTOSCALER_SCALE_DOWN_DELAY_AFTER_FAILURE: スケール ダウンの失敗後にクラスタ オートスケーラがスケール ダウン スキャンを再開するまで待機する時間です。
-
AUTOSCALER_SCALE_DOWN_UNNEEDED_TIME: クラスタ オートスケーラが対象ノードをスケール ダウンするまでに待機する必要がある時間です。
-
AUTOSCALER_MAX_NODE_PROVISION_TIME: クラスタ オートスケーラがノードのプロビジョニングを待機する最長時間です。
-
AUTOSCALER_*_SIZE: 「dev」クラスタなど、単一のワーカー ノードを持つクラスタの場合は、「AUTOSCALER_MIN_SIZE_0」と「AUTOSCALER_MAX_SIZE_0」のみを設定します。「prod」など複数のcontrol-planeノードが存在する場合は、control-planeノード分設定します。
- AUTOSCALER_MIN_SIZE_*: workerノードの最小個数です。今回は「1」に設定しています。
- AUTOSCALER_MAX_SIZE_*: 自動スケーリングが実行された際のworkerノードの最大個数です。今回は「5」に設定しています。
-
設定ファイルの確認として以下のコマンドを実行してください。
MuNeNiCK [ ~ ]$ diff tkg21mc01.yaml tkg21wc01.yaml
21,22c21,22
< CLUSTER_NAME: tkg21mc01
< CLUSTER_PLAN: dev
---
> CLUSTER_NAME: tkg21wc01
> CLUSTER_PLAN: prod
59c59
< VSPHERE_FOLDER: /Datacenter/vm/TKG/Management
---
> VSPHERE_FOLDER: /Datacenter/vm/TKG/Workload
71a72,91
> #! ---------------------------------------------------------------------
> #! Autoscaler related configuration
> #! ---------------------------------------------------------------------
> ENABLE_AUTOSCALER: true
> AUTOSCALER_MAX_NODES_TOTAL: "0"
> AUTOSCALER_SCALE_DOWN_DELAY_AFTER_ADD: "10m"
> AUTOSCALER_SCALE_DOWN_DELAY_AFTER_DELETE: "10s"
> AUTOSCALER_SCALE_DOWN_DELAY_AFTER_FAILURE: "3m"
> AUTOSCALER_SCALE_DOWN_UNNEEDED_TIME: "10m"
> AUTOSCALER_MAX_NODE_PROVISION_TIME: "15m"
>
> # Each min/max pair (0,1,2) corresponds to an availability zone.
> # If you have a 'dev' cluster, you only need to fill in the min/max size for '0'.
> # If you have a 'prod' cluster, you need to fill in all three pairs.
> AUTOSCALER_MIN_SIZE_0: 1
> AUTOSCALER_MAX_SIZE_0: 5
> AUTOSCALER_MIN_SIZE_1: 1
> AUTOSCALER_MAX_SIZE_1: 5
> AUTOSCALER_MIN_SIZE_2: 1
> AUTOSCALER_MAX_SIZE_2: 5Workloadクラスタのデプロイ
- 以下のコマンドを実行してください。しかし、デプロイされないと思います。これはTKG2.1からの変更点で、yamlのフォーマットが古いために起こります。
MuNeNiCK [ ~ ]$ tanzu cluster create -f tkg21wc01.yaml
Validating configuration...
Warning: Pinniped configuration not found; Authentication via Pinniped will not be set up in this cluster. If you wish to set up Pinniped after the cluster is created, please refer to the documentation.
Legacy configuration file detected. The inputs from said file have been converted into the new Cluster configuration as '/home/MuNeNiCK/.config/tanzu/tkg/clusterconfigs/tkg21wc01.yaml'
To create a cluster with it, use
tanzu cluster create --file /home/MuNeNiCK/.config/tanzu/tkg/clusterconfigs/tkg21wc01.yaml- ログに表示されている「To create a cluster with it, use」以下のコマンドを実行してください。これによりWorkloadクラスタのデプロイが開始します。
MuNeNiCK [ ~ ]$ tanzu cluster create --file /home/MuNeNiCK/.config/tanzu/tkg/clusterconfigs/tkg21wc01.yaml
Validating configuration...
Warning: Pinniped configuration not found; Authentication via Pinniped will not be set up in this cluster. If you wish to set up Pinniped after the cluster is created, please refer to the documentation.
creating workload cluster 'tkg21wc01'...Workloadクラスタのデプロイに失敗したら。
- 以下のコマンドを実行し、Workloadクラスタの削除をします。
MuNeNiCK [ ~ ]$ tanzu cluster delete tkg21wc01
Deleting workload cluster 'tkg21wc01'. Are you sure? [y/N]: y
successfully deleted autoscaler resources from management cluster
Workload cluster 'tkg21wc01' is being deleted- 以下のコマンドを実行し、削除の確認をしてください。
MuNeNiCK [ ~ ]$ tanzu cluster list
NAME NAMESPACE STATUS CONTROLPLANE WORKERS KUBERNETES ROLES PLAN TKR- 設定やサーバの状態を見直し、再度クラスタのデプロイを実行してください。この際、「–timeout 時間」オプションを指定することもできます。
Workloadクラスタのデプロイの確認
BootStrapマシンでのログの確認
- BootStrapマシン上のログに「Workload cluster ‘tkg21wc01’ created」と表示されていれば正常にデプロイできています。
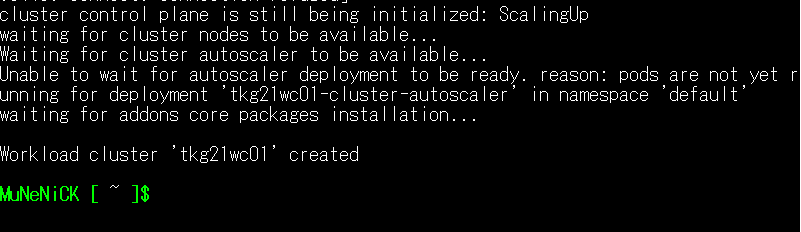
Tanzu CLIコマンドで確認
- BootStrapマシンにアクセスし、以下のコマンドを実行してください。
MuNeNiCK [ ~ ]$ tanzu cluster list
NAME NAMESPACE STATUS CONTROLPLANE WORKERS KUBERNETES ROLES PLAN TKR
tkg21wc01 default running 3/3 3/3 v1.24.10+vmware.1 <none> prod v1.24.10---vmware.1-tkg.2vCenterにアクセスして確認
- vCenter Serverにアクセスし、「TKG」→「Workload」フォルダ内に仮想マシンが作成されていることを確認してください。
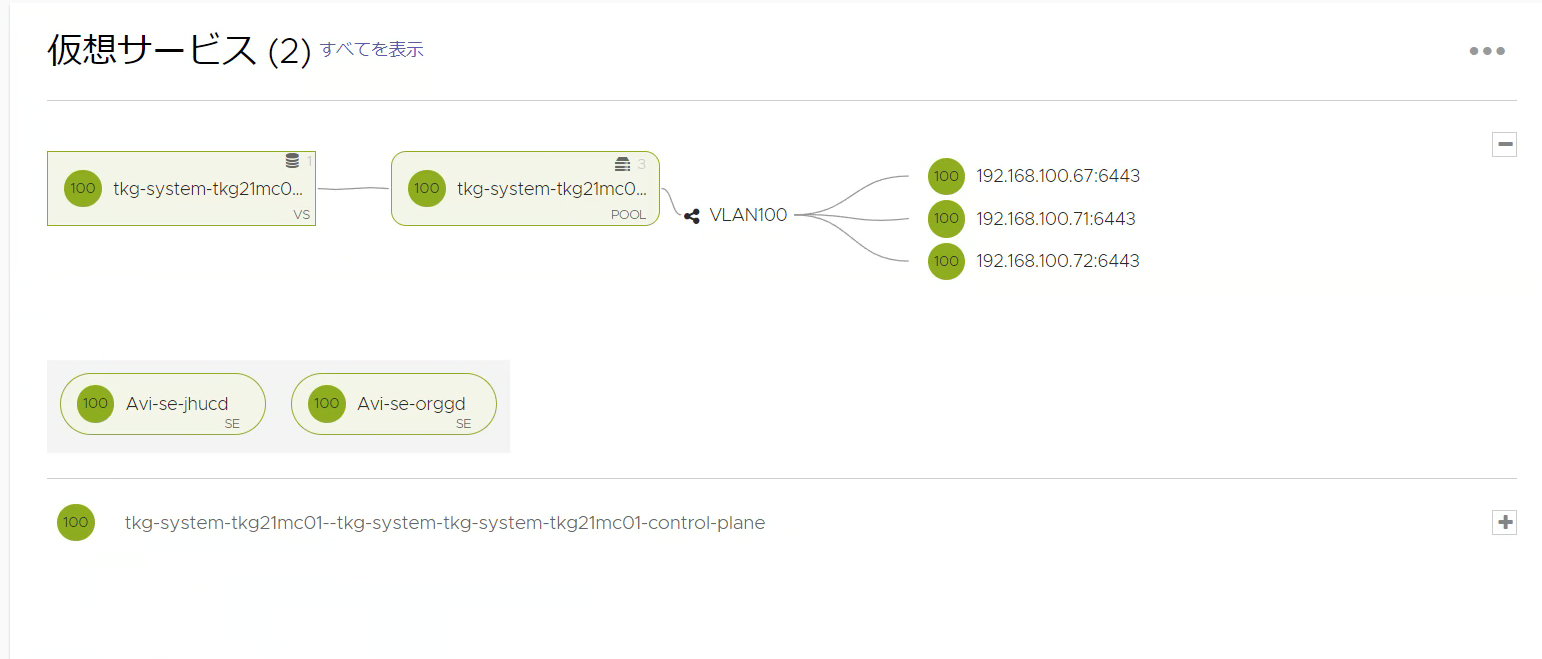
NSX ALBにアクセスして確認
- NSX ALBにログインし、「アプリケーション」→「ダッシュボード」にアクセスすることでデプロイを確認できます。
Workloadクラスタへの接続
Workloadクラスタに接続し、クラスタの管理を行うためいくつかっも操作が必要になります。
- まず、以下のコマンドを実行してkubeconfigを取得してください。
MuNeNiCK [ ~ ]$ tanzu cluster kubeconfig get tkg21wc01 --admin
Credentials of cluster 'tkg21wc01' have been saved
You can now access the cluster by running 'kubectl config use-context tkg21wc01admin@tkg21wc01'- 次にログに出力されている通り、以下のコマンドを実行します。
MuNeNiCK [ ~ ]$ kubectl config use-context tkg21wc01-admin@tkg21wc01
Switched to context "tkg21wc01-admin@tkg21wc01".- 以下のコマンドを実行して現在のコンテキストを確認してください
MuNeNiCK [ ~ ]$ kubectl config get-contexts
CURRENT NAME CLUSTER AUTHINFO NAMESPACE
tkg21mc01-admin@tkg21mc01 tkg21mc01 tkg21mc01-admin
* tkg21wc01-admin@tkg21wc01 tkg21wc01 tkg21wc01-admin- コンテキストを使用してクラスタのノードを確認します。以下のコマンドを実行してください。
MuNeNiCK [ ~ ]$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
tkg21wc01-md-0-bzhsf-7876ffdcb7-8nkg8 Ready <none> 8h v1.24.10+vmware.1
tkg21wc01-md-1-hxlzn-7cbf69bd58-4tqjc Ready <none> 8h v1.24.10+vmware.1
tkg21wc01-md-2-nrn7z-6bb84c66c-gxjgx Ready <none> 8h v1.24.10+vmware.1
tkg21wc01-mdcg5-52ld6 Ready control-plane 8h v1.24.10+vmware.1
tkg21wc01-mdcg5-n46zx Ready control-plane 7h53m v1.24.10+vmware.1
tkg21wc01-mdcg5-zkqg8 Ready control-plane 8h v1.24.10+vmware.1Podの動作確認
WorkloadクラスタおよびNSX ALBが正常に動作することを確認するために以下の手順を実行してください。
- 以下のコマンドを実行してテストを作成してください。
MuNeNiCK [ ~ ]$ kubectl run hello --image=gcr.io/google-samples/node-hello:1.0
pod/hello created- 以下のコマンドでPodの起動を確認してください。(起動までに数分かかります)
MuNeNiCK [ ~ ]$ kubectl get pods
NAME READY STATUS RESTARTS AGE
hello 1/1 Running 0 101s- NSX ALBのLoad Balancerからアクセスできるように以下のコマンドを実行してPodに対応したServiceを作成してください。
MuNeNiCK [ ~ ]$ kubectl expose pod hello --type=LoadBalancer --port=80 --target-port=8080
service/hello exposed- 以下のコマンドでServiceの起動と割り当てられたExternal-IPアドレスを確認してください。
MuNeNiCK [ ~ ]$ kubectl get service hello
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
hello LoadBalancer 100.65.13.125 192.168.100.105 80:31362/TCP 108s-
ブラウザを起動し、先程確認したIPアドレスにアクセスしてください。アクセスできましたら、正常にWorkloadクラスタおよびNSX ALBのロードバランサが動作していることがわかります。
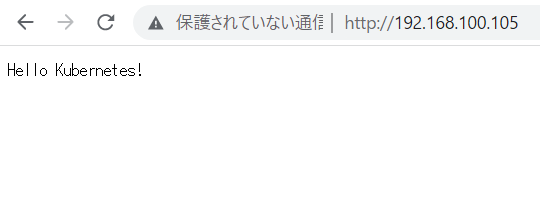
-
NSX ALBにログインし、「アプリケーション」→「ダッシュボード」でも確認することができます。
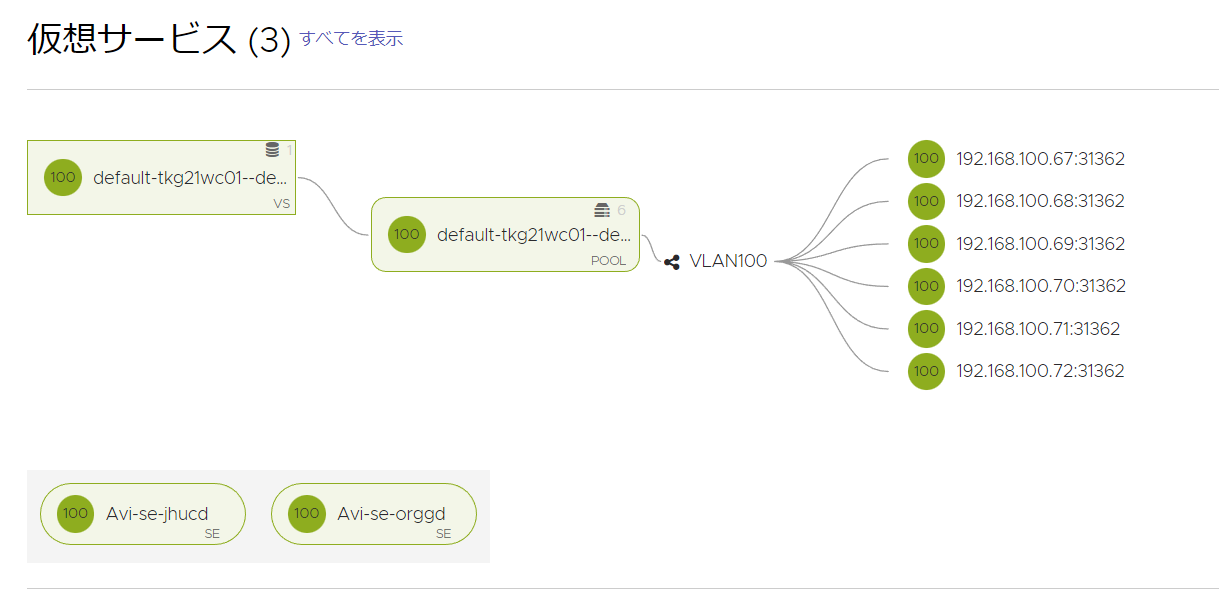
-
最後に以下のコマンドを実行し、作成したPodとServiceを削除してください。これらの削除を行うとNSX ALBの仮想サービスも自動的に削除されます。
MuNeNiCK [ ~ ]$ kubectl delete pod hello
pod "hello" deleted
MuNeNiCK [ ~ ]$ kubectl get pod
No resources found in default namespace.
MuNeNiCK [ ~ ]$ kubectl delete service hello
service "hello" deleted
MuNeNiCK [ ~ ]$ kubectl get service hello
Error from server (NotFound): services "hello" not found
AutoScalerの設定(オプション)
AutoScalerの設定を行っている場合、この項目を実施してください。
- 以下のコマンドを実行してマネジメントクラスタのコンテキストに切り替えてください。
MuNeNiCK [ ~ ]$ kubectl config use-context tkg21mc01-admin@tkg21mc01
Switched to context "tkg21mc01-admin@tkg21mc01".- 以下のコマンドを実行し、MachineDeploymentの名前を確認してください。
MuNeNiCK@BootStrap [ ~ ]$ kubectl get md
NAME CLUSTER REPLICAS READY UPDATED UNAVAILABLE PHASE AGE VERSION
tkgwc01-md-0-24cdt tkgwc01 1 1 1 0 Running 14h v1.25.7+vmware.2
tkgwc01-md-1-85fmf tkgwc01 1 1 1 0 Running 14h v1.25.7+vmware.2
tkgwc01-md-2-wfhc7 tkgwc01 1 1 1 0 Running 14h v1.25.7+vmware.2- 以下のコマンドを使用して、すべてのMachineDeploymentの最小デプロイ数を指定してください。
kubectl annotate machinedeployment MD-NAME cluster.k8s.io/cluster-api-autoscaler-node-group-min-size="MIN-SIZE"
- 以下のコマンドを使用して、すべてのMachineDeploymentの最小デプロイ数を指定してください。
kubectl annotate machinedeployment MD-NAME cluster.k8s.io/cluster-api-autoscaler-node-group-max-size="MAX-SIZE"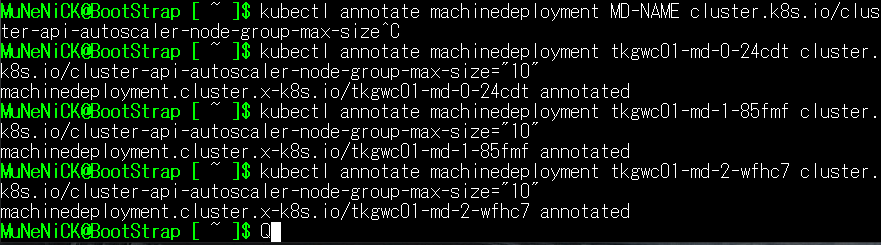
- 以下のコマンドを実行してAutoScalerの動作のReadyが1/1になっていることを確認してください。
MuNeNiCK@BootStrap [ ~ ]$ kubectl get deployment
NAME READY UP-TO-DATE AVAILABLE AGE
tkgwc01-cluster-autoscaler 1/1 1 1 14h以上でTKGクラスタおよびNSX ALBの動作確認は完了です。
次回
BootStrapマシンは一時的なマシンであるため、基本的にManagementクラスタおよびWorkloadクラスタをデプロイしたら削除するそうです。そのため、Tanzu CLIを実行し、2つのクラスタを管理するマシンを別途作成する必要があるようです。次回は別マシンでTanzu CLIを実行し、クラスタを管理する方法を紹介します。この段階ではまだBootStrapマシンを削除しないでください。
https://www.munenick.me/blog/tkg-nsx-alb-04